


狂飙13天:开源DeepSeek如何撼动全球AI市场;美2月1日起对墨加商品征收25%关税;美国20多年来“最严重空难”已打捞出41具遗体;2812美元!金价创10年来“最佳一月表现” 一周国际财经
时间: 2025-04-06 22:03:35 | 作者: 中国传统医疗器械
在DeepSeek的冲击下,当地时间1月31日,OpenAI紧急推出了全新推理模型o3-mini,并首次向免费用户开放。同时,阿尔特曼承认,DeepSeek是一个非常好的模型,OpenAI一马当先的优势会比以前减弱。


◆从1月20日推理模型DeepSeek-R1开源至今13天来,DeepSeek引起全球的惊讶,英伟达市值一周蒸发5520亿美元,硅谷巨头的恐慌,华尔街的焦虑。DeepSeek选择了与OpenAI截然不同的模型训练路线,并凭借高性能、低价格与开源对AI格局造成了三重冲击,动摇了英伟达的“算力信仰”。当地时间1月31日,OpenAI紧急推出了全新推理模型o3-mini,并首次向免费用户开放。同时,阿尔特曼承认,DeepSeek是一个非常好的模型,OpenAI一马当先的优势会比以前减弱。AI的未来,何去何从?对此,《每日经济新闻》记者深度解析DeepSeek在短短的13天是如何撼动全球AI市场。
◆美国2月1日起对墨加商品征收25%关税;美国20多年来“最严重空难”已打捞出41具遗体;2812美元!金价创10年来“最佳一月表现”;KRAS癌症疗法取得突破,生物科学技术公司Silexion周涨逾193%。更多内容,尽在《一周国际财经》。

2025年1月中旬,英伟达CEO黄仁勋的中国之行备受瞩目。从北京到深圳,再到台中和上海,这位AI时代的“卖铲人”每到一处都掀起一阵热潮。然而,就在距离英伟达上海办公室仅200公里的杭州,一场足以撼动AI产业格局的风暴正在悄然酝酿。彼时,身家1200亿美元的黄仁勋或许并未意识到,一家名为深度求索(DeepSeek)的低调中国公司,即将在7天后成为英伟达的“黑天鹅”。
从1月20日推理模型DeepSeek-R1开源至今13天来,DeepSeek引起全球的惊讶,英伟达市值一周蒸发5520亿美元,硅谷巨头的恐慌,华尔街的焦虑。
1月21日,特朗普在白宫宣布启动四年总投资5000亿美元、名为“星际之门”(Stargate)的AI基础设施计划。
随后,英伟达自己的科学家Jim Fan率先解读出了它的颠覆性意义。他说:“我们生活在这样一个时代:由非美国公司延续OpenAI最初的使命做真正开放的前沿研究、为所有人赋能。”
但临近周末,DeepSeek突然成为科技圈、投资圈和媒体圈讨论的对象。摩根大通分析师Joshua Meyers说:“周五,我收到的问题95%都是围绕Deepseek的。”
但为时已晚,英伟达的跌势慢慢的开始。1月24日(周五)英伟达股价跌去3.12%。1月27日(周一),英伟达遭遇17%的“历史性”大跌,市值蒸发近6000亿美元,黄仁勋的个人财富一夜之间缩水208亿美元。

1月24日(周五)发布的聊天机器人竞技场(Chatbot Area)榜单上,DeepSeek-R1综合排名第三,与OpenAI的ChatGPT o1并列。在高难度提示词、代码和数学等技术性极强的领域以及风格控制方面,DeepSeek-R1位列第一。
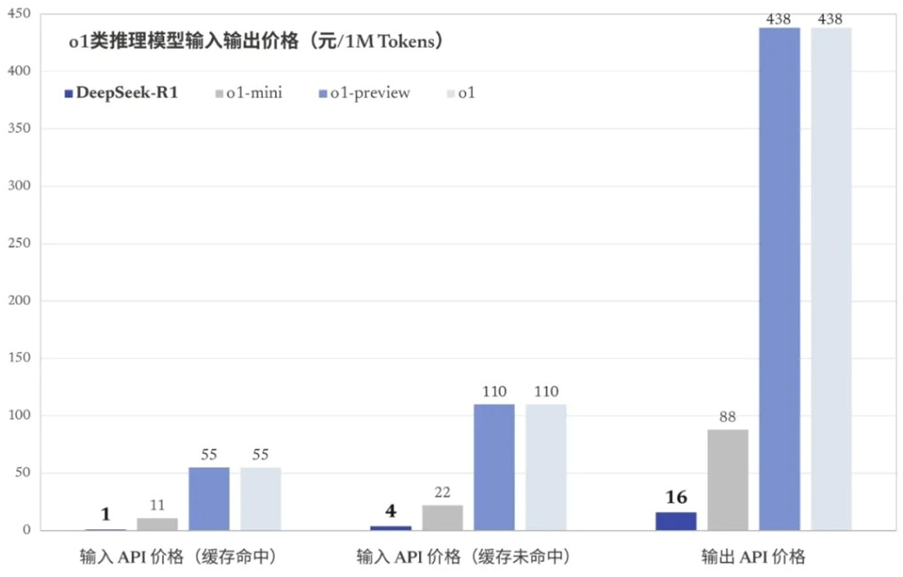
DeepSeek移动应用和网页端免费,而能力相当的 ChatGPT o1一个月200美元。
DeepSeek-R1完全开源,任何人都能自由地使用、修改、分发和商业化该模型,彻底打破了以往大型语言模型被少数公司垄断的局面,将AI技术交到了广大开发者和研究人员的手中。
1月24日,著名投资公司A16z的创始人马克安德森发文称,Deepseek-R1是他见过的最令人惊叹、最令人印象非常深刻的突破之一,而且还是开源的,它是给世界的一份礼物。
最具煽动性的评价来自Scale AI创始人亚历山大王(Alexandr Wang)。他说:过去十年来,美国可能一直在AI竞赛中领先于中国,但DeepSeek的AI大模型发布可能会“改变一切”。
他们开始思考,如果DeepSeek的低成本训练有效,是否意味着巨头们在算力上的投入不值得了。如果不需要疯狂投入,市场对英伟达的业绩预期还有支撑吗?
正如投行Jeffreies股票分析师Edison Lee团队1月27日在研报中所说,如今美国AI企业的管理层可能面临更加大的压力。他们要回答一个问题:进一步提升AI资本支出是否是合理的?
硅谷公司还面临着投资者的拷问。1月27日上午,高盛分析师Keita Umetani和多名投资者进行了谈话,不少投资者质疑:“如果没有回报,还能证明资本支出的合理吗?”
摩根大通分析师Joshua Meyers说,DeepSeek的(低成本)并不代表扩张的终结,也不意味着不再需要更加多的算力。
花旗分析师Atif Malik团队称,尽管DeepSeek的成就可能是开创性的,但如果没用先进的GPU对其进行微调和/或通过蒸馏技术构建最终模型所基于的底层大模型,DeepSeek的成就就不可能实现。
DeepSeek-R1的训练成本尚未公布。因此,一个月前(去年12月26日)发布的开源模型DeepSeek-V3成为主要分析对象。
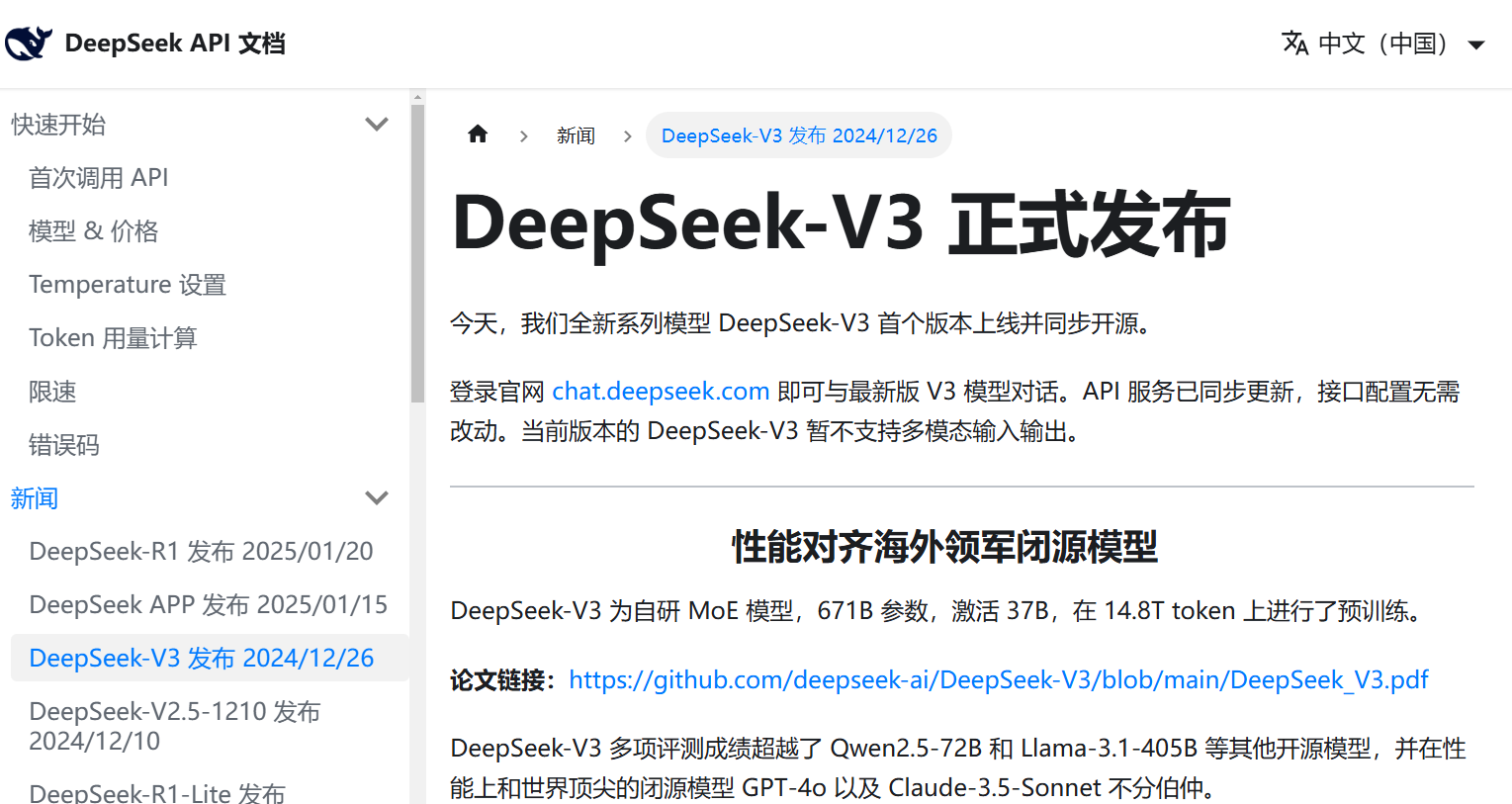
DeepSeek-V3仅使用2048块英伟达H800 GPU,在短短两个月内训练完成。H800是英伟达中国市场的AI芯片,在性能上不及先进的H200、H100等。
官方声称的558万美元只是训练开销,真实总支出尚无定论。《DeepSeek-V3技术报告》中精确指出:请注意,上述成本仅包括 DeepSeek-V3的正式训练,不包括与架构、算法或数据相关的先前的研究或精简实验的成本。
“当部门里一个高管的薪资就超过训练整个DeepSeek-V3的成本,而且这样的高管还有数十位,他们该如何向高层交代?”Meta员工如是说。
DeepSeek训练成本低,一个重要原因是使用了数据蒸馏技术(Distillation)。数据蒸馏是将复杂模型的知识提炼到简单模型。通过已有的高质量模型来合成少量高质量数据,并作为新模型的训练数据。
根据技术报告,DeepSeek-V3利用DeepSeek-R1模型生成数据后,再使用专家模型来蒸馏生成最终的数据。
不过,数据蒸馏技术在行业内充满争议。南洋理工大学研究人员王汉卿向《每日经济新闻》记者表示,蒸馏技术存在一个巨大缺陷,就是被训练的模型(即“学生模型”)没法真正超越“教师模型”。OpenAI也把DeepSeek的蒸馏当作靶子加以攻击。
1月29日,OpenAI首席研究官Mark Chen发帖称,“外界对(DeepSeek的)成本优势的解读有些过头”。
资深业内人士向每经记者分析称,DeepSeek-V3创新性地同时使用了FP8、MLA(多头潜在注意力)和MoE(利用混合专家架构)三种技术。
相较于其他模型使用的MoE架构,DeepSeek-V3的更为精简有效,每次只需要占用很小比例的子集专家参数就能够实现计算。这一架构的更新是2024年1月DeepSeek团队提出的。
MLA机制则是完全由DeepSeek团队自主提出、并最早作为核心机制引入了DeepSeek-V2模型上,极大地降低了缓存使用。
2024年12月,清华大学计算机系长聘副教授、博士生导师喻纯在谈及中国AI发展时向《每日经济新闻》表示,中国在AI应用层有很大的优势,擅长“从1到10”,但原始创造新兴事物的能力(从0到1)还有待提高。
DeepSeek带来的最大“震撼”,是蹚出了一条与OpenAI截然不同的模型训练路径。
传统上,监督微调 (Supervised Fine-Tuning,简称 SFT)作为大模型训练的核心环节,需要先通过人工标注数据来进行监督训练,再结合强化学习来优化,这一范式曾被认为是 ChatGPT成功的关键技术路径。
DeepSeek为何不走捷径,而是寻求一条与OpenAI完全不同技术路线?背后的理由可以从创始人梁文锋的理想中探寻。
《每日经济新闻》记者通过调查了解到,DeepSeek规定员工不能对外接受采访。即便是DeepSeek用户群里的客服工作人员在解答群友疑问时也是小心翼翼,惜字如金。
寻找梁文锋的人更是踏破铁鞋。外界对他的了解大多来自于2023年5月和2024年7月《暗涌》对他的专访。专访文章将他称为“一个更极致的中国技术理想主义者”。和OpenAI创始人山姆阿尔特曼(Sam Altman)一样,梁文锋的“目的地”是通用AI(AGI)。然而,梁文锋的理想不在于目的地,而是如何通往目的地。
DeepSeek选择“不做垂类和应用,而是做研究,做探索”“做最难的事”“解决世界上最难的问题”。
他说:“我们大家常常说中国AI和美国有一两年差距,但真实的gap是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。”
对于选择和OpenAI不一样的路,梁文锋的口气中充满乐观:ChatGPT诞生在OpenAI“也有历史的偶然性”“OpenAI也不是神,不可能一直冲在前面”。
当地时间周一(1月27日)晚间,OpenAI首席执行官山姆阿尔特曼终于对DeepSeek给出了他的评价。他在社交平台X上连发三条值得玩味的帖子。
首先,他重申了自己的目标AGI。甚至比梁文锋更进一步,要“超越”AGI。
其次,他捍卫了自己的“路线”算力不仅重要,而且前所未有地重要。
最后,他将DeepSeek-R1称作“一位新对手”,并表示“我们当然会推出更好的模型”。
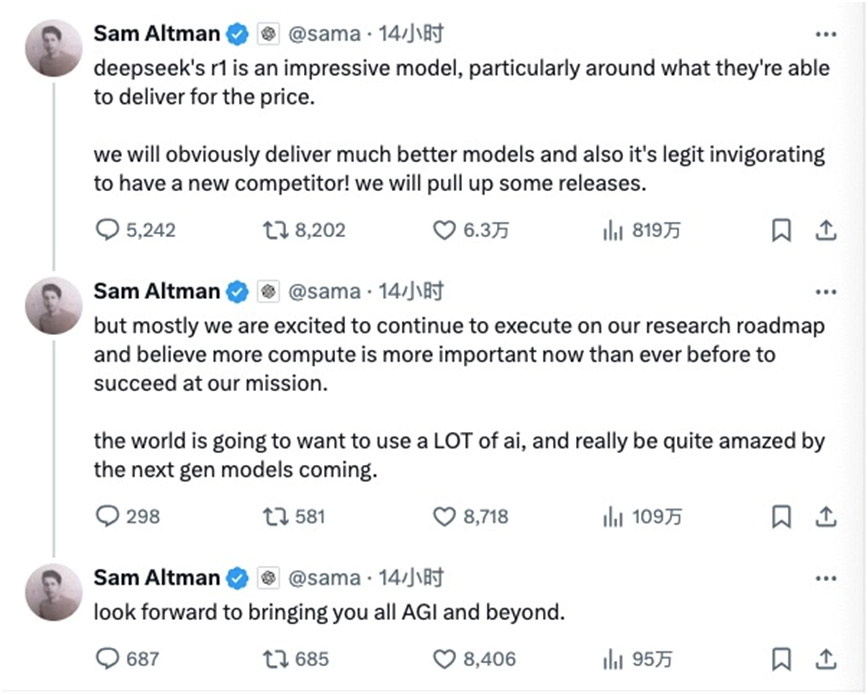
当地时间1月31日,在携一众高管在reddit上举行AMA(问我任意的毛病)活动时,阿尔特曼正式承认DeepSeek是一个非常好的模型,OpenAI会制作出更好的模型,但一马当先的优势会比以前减弱。
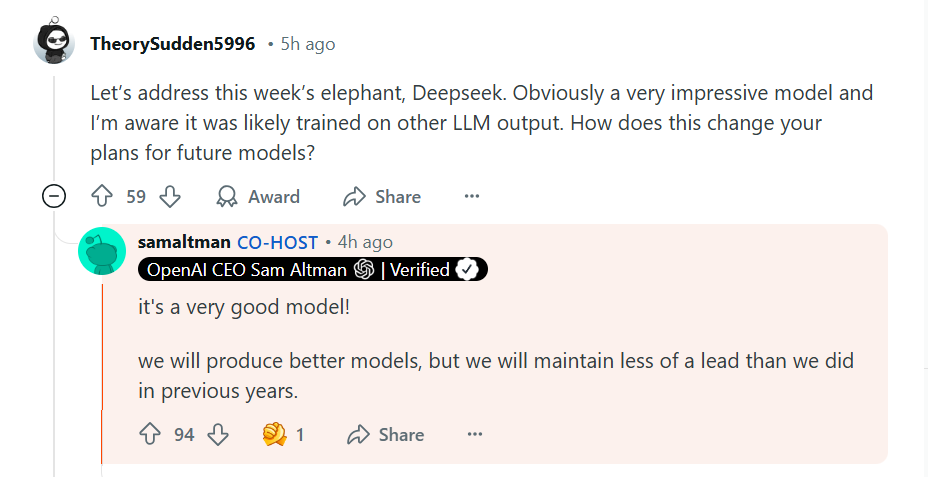
这是否是山姆阿尔特曼向DeepSeek下的“宣战书”?他想较量的不仅关于谁是“更好的模型”,更是想用“大力出奇迹”的技术与“聪明”的技术进行一场比拼。
一边是硅谷、华尔街都在激辩DeepSeek的影响;另一边,科技巨头已经下场无缝连接DeepSeek-R1模型服务。
先是微软,当地时间1月29日,将DeepSeek-R1模型添加到其Azure AI Foundry,开发的人能用新模型来测试和构建基于云的应用程序和服务。
虽然微软是OpenAI的深度投资者且有很多合作,但在产品商业化上它依然选择多样性的模型。目前Azure的平台上既有OpenAI的GPT系列、Meta的Llama系列、Mistral的模型,现在新增了DeepSeek。
再然后是英伟达于当地时间1月31日官宣,DeepSeek-R1模型已作为NVIDIA NIM微服务预览版,在英伟达面向开发者的网站上发布。
英伟达还在官网中表示,DeepSeek-R1是一个具有最先进推理能力的开放模型。DeepSeek-R1等推理模型不会提供直接响应,而是对查询进行多次推理,采用思路链、共识和搜索方法来生成最佳答案。此前,1月28日,英伟达(中国)在对每经记者的回应中说到:“推理过程需要大量英伟达GPU和高性能网络。”
想要在AI算力领域挑战英伟达的AMD也毫不犹豫为DeepSeek“站台”。1月25日,AMD宣布,DeepSeek-V3模型已集成至AMD InstinctGPU上,并借助SGLang进行了性能优化。此次集成将助力加速前沿AI应用与体验的开发。
阿斯麦总裁兼CEO富凯1月29日表示:“任何减少相关成本的事情,对阿斯麦来说都是好消息”,因为更低的成本意味着更多的应用场景,更多应用意味着更多芯片。
2020年1月,OpenAI发表论文《神经语言模型的规模法则》(Scaling Laws for Neural Language Models)。规模法则表明,通过增加模型规模、数据量和计算资源,可以明显提升模型性能。在AI领域,规模法则被俗称为“大力出奇迹”,也是OpenAI的制胜法宝。
2024年底,AI界传出大模型进化遭遇“数据墙”的消息。美国技术研究公司Epoch AI预测,网络上可用的高质量文本数据可能会在2028年耗尽。图灵奖获得者杨立昆(Yann LeCun)和OpenAI前首席科学家伊利亚苏茨克维(Ilya Sutskever)等人直言,规模法则(Scaling Law)已触及天花板。
“大力出奇迹”的忠实拥趸硅谷巨头们开始将千亿美元级的资本投入算力。这场“算力竞赛”的疯狂程度从下面这一些数据中可见一斑。
但是,DeepLearning创始人吴恩达1月29日撰文提醒称,扩大规模(Scaling up)并非是实现AI进步的唯一途径。一直以来人们过度关注扩大规模,而没有以更细致入微的视角,充分重视实现进步的多种不同方式。但算法创新正使训练成本大幅下降。
DeepSeek的出现让人们开始重新审视开源的价值和风险,以及AI产业的竞争格局。这场由DeepSeek引发的“冲击波”,将对全球AI产业产生深远的影响。
未来的AI世界,是“大力出奇迹”的继续狂飙,还是“聪明”技术的异军突起?是巨头垄断的固化,还是百花齐放的繁荣?
DeepSeek出现,让AI界开始真正严肃地思考未来:是继续烧钱豪赌,还是让AI成果商业化、平民化和普惠化?
1月31日,Hugging Face联合发起人兼CEO托马斯・沃尔夫(Thomas Wolf)说:“我认为人们正在从对模型的狂热中冷静下来,因为他们明白,得益于开源很多这类模型将会免费且可自由获取。”
巧合地是,同日,OpenAI正式推出了全新推理模型o3-mini,并首次向免费用户开放推理模型。这是OpenAI推理系列中最新、成本效益最高的模型,现在已经在ChatGPT和API中上线mini正式推出之时,Sam Altman携一众高管在reddit回答网友问题时,罕见承认OpenAI过去在开源方面一直站在“历史错误的一边”。Altman表示:“需要想出一个不同的开源策略”。

在当地时间1月30日的记者会上,尽管没提供证据,但美国总统特朗普批评飞行员和塔台空管员,认定事故原因与美国联邦政府倡导多元化的一系列举措有关。身为共和党人的特朗普指出,人拜登、奥巴马在执政期间推动的一系列多元化政策导致联邦航空管理局招聘标准下降、工作人员能力不够,是撞机事故发生的深层次原因。对此,人和一些民权组织指责特朗普正在“把空难政治化”。

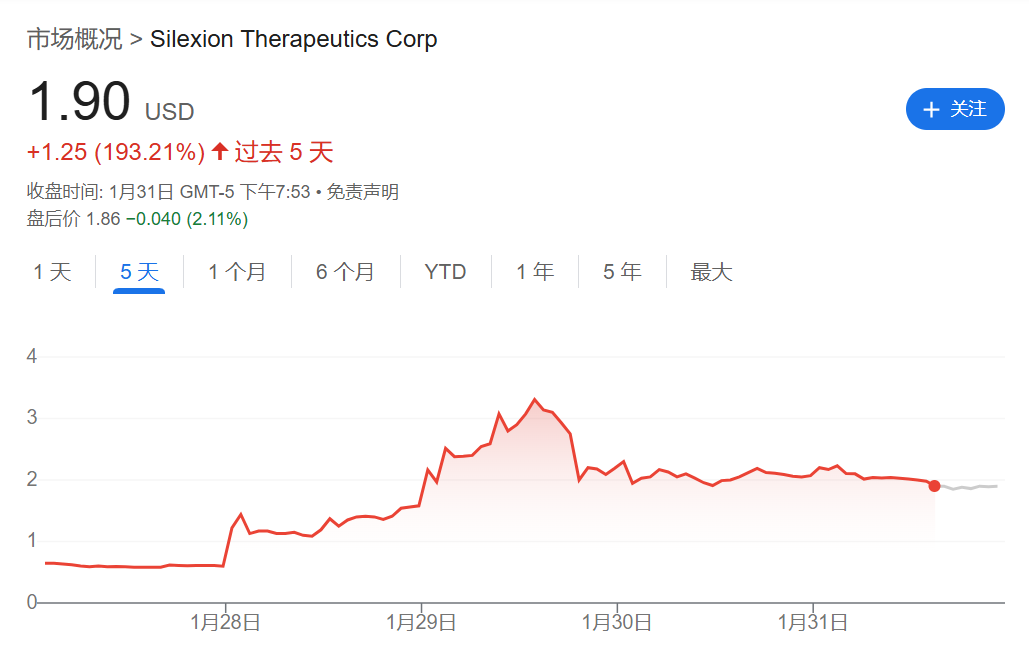
Silexion Therapeutics首席科学官Mitchell Shirvan博士强调SIL-204有潜力治疗晚期癌症。公司计划扩大其针对KRAS靶点癌症的开发策略,进一步研究该药物对转移性进展的影响。公司计划很快开始SIL-204的毒理学研究,并准备在2026年上半年进入II期和III期临床试验。
近期,Silexion Therapeutics 对其资本结构可以进行了重大调整,包括反向股票拆分和未行使认股权证的调整。股东以压倒性多数批准了1比9的反向股票拆分,这整合了公司已发行和流通的普通股,以及授权但未发行的股份。公司董事会实施这一战略举措,旨在使其资本结构与运营和财务策略保持一致。

美股“七姐妹”中,英伟达周五收跌3.67%,市值一夜蒸发1122亿美元(约合人民币8136亿元)。此前,周一美股收盘,英伟达下跌近17%,收报118.42美元,单日的市值蒸发规模达到5890亿美元,为美国股市历史上最大。本周,英伟达累跌15.8%,市值蒸发5520亿美元。
特别提醒:如果个人会使用了您的图片,请作者与本站联系索取稿酬。如您不希望作品出现在本站,可联系我们要求撤下您的作品。
特朗普的第一周;中国大模型震惊硅谷;加州新火情致数万民众撤离;OpenAI创始成员给智能体“泼冷水”;特斯拉、微软、Meta财报来袭 一周国际财经
特朗普的第一周;中国大模型震惊硅谷;加州新火情致数万民众撤离;OpenAI创始成员给智能体“泼冷水” 一周国际财经
美国爆发大规模反特朗普!特朗普回应股市:暗示自己是“故意”的,喊话美国人民“挺住”
|
|
联系方式
|
